코틀린은 내가 정말로 사랑하는 언어이다. 내가 코틀린에서 가장 좋아하는 부분은 다음과 같다.
1. 자바와 100% 호환 가능
2. Collection funtion
3. Scope funtion
4. null Safe 체크
5. 간결함
정말 사랑하지 않을래야 않을수가 없다. 개인적으로 java 사이드 협업1개와 다른 나머지 프로젝트는 Kotlin으로 진행하고있는데 Java와 Kotlin의 차이가 확 느껴진다.
Bulider 패턴이 없는 클래스 인자를 정의 할때 자바 같은 경우
dialog = new Dialog(context);
dialog.setContentView(....);
dialog.set..
dialog.set..
dialog.set..
이런식으로 반복해서 정의해야하는 경우가 있는데 Kotlin 은
val dialog = Dialog(context)
dialog.apply{
setContentView(.)
...
...
}
이런식으로 스코프영역을 활용할 수가 있다.
스코프를 지정해서 사용할 수 있다.
코틀린을 사용하면 이렇게도 많이 사용할 수 있다.
Dialog(context).apply{
..
..
..
show()
}
그외 let, run, also, with 등등 응용하면 좋은 스코프 함수들이 있다.
이를 어떻게 응용하느냐는 개발자의 몫이겠지만,
스코프 함수 말고도 널세이프 체크나 깔끔한 람다,
타입 추론 기능,고차함수 등등 응용하면 좋은것들이 많다.
진정한 코틀린 고수들은 프로그래밍에서 oop개념을 잘 사용하면서
함수형 언어의 장점을 최대한 살리는것을 볼 수가 있다. (존경스럽습니다.)
자바와 코틀린을 오가면 나도 모르게 코틀린을 자바처럼 이용하는 습관이 생겨버리는데
이 습관을 중간중간 교정해주기 위해서
최근에 코틀린으로 알고리즘을 풀어가면서 그 깊이를 열심히 파고 있습니다.
코틀린의 장점을 최대한 활용한 알고리즘 코드들을 이 블로그에 계속 기록해서
코틀린을 코틀린스럽게 사용하는것을 기록해가며 복습해볼 예정입니다.
알고리즘 1) 프로그래머스 -위장-
https://programmers.co.kr/learn/courses/30/lessons/42578


입출력 예
clothesreturn
| [["yellowhat", "headgear"], ["bluesunglasses", "eyewear"], ["green_turban", "headgear"]] | 5 |
| [["crowmask", "face"], ["bluesunglasses", "face"], ["smoky_makeup", "face"]] | 3 |
입출력 예 설명
예제 #1
headgear에 해당하는 의상이 yellow_hat, green_turban이고
eyewear에 해당하는 의상이 blue_sunglasses이므로
아래와 같이 5개의 조합이 가능합니다.
---
1. yellow_hat 2. blue_sunglasses 3. green_turban
4. yellow_hat + blue_sunglasses 5. green_turban + blue_sunglasses
예제 #2
face에 해당하는 의상이 crow_mask, blue_sunglasses,
smoky_makeup이므로 아래와 같이 3개의 조합이 가능합니다.
---
1. crow_mask 2. blue_sunglasses 3. smoky_makeup
코틀린으로 풀이한건 다음과 같습니다.
fun solution(clothes: Array<Array<String>>)=
clothes.groupBy { it[1] }.values.fold(1) { acc, v -> acc * (v.size + 1) } - 1
잘라서 보기 (1)
clothes.groupBy { it[1] }
Kotlin 함수중에 groupBy라는 함수가 존재하는데,
groupBy의 설명은 아래와 같습니다.
https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.collections/group-by.html
groupBy - Kotlin Programming Language
kotlinlang.org
groupBy의 내부는 이러한데,
public inline fun <T, K> Iterable<T>.groupBy(keySelector: (T) -> K): Map<K, List<T>> {
return groupByTo(LinkedHashMap<K, MutableList<T>>(), keySelector)
}Iterable의 확장함수 입니다.
인자로 keySelector라는 고차함수를 받고 있고, Map<K,List<T>> 로 반환을 해줍니다.
즉 해당 coleaction을 LikedHashMap으로 변환해주는 함수 입니다.
groubBy {}인자안에 인덱스 기준으로 key를 설정하면 해당 key를 기준으로 Map를 만들어줍니다.
다시 코틀린 풀이로 돌아오면 clothes가 2차원 배열임을 알 수가 있습니다.
val clothes= arrayOf(arrayOf("yellowhat","headgear"),
arrayOf("bluesunglasses", "eyewear"),
arrayOf("green_turban", "headgear"))
val clothes= arrayOf(arrayOf("yellowhat","headgear"),
arrayOf("bluesunglasses", "eyewear"),
arrayOf("green_turban", "headgear"))예제로 넣을 clothes 2차원 배열의 값은 이렇습니다.
2차원 배열안의 1차원 배열 [0]는 실제 옷, [1]는 종류 이렇게 나뉘어있습니다.
그래서 groupby{it[1]}를 한다면 장르 key값 으로 Map을 만들어줍니다.
clothes.groupBy { it[1] } 결과: {headgear=yellowhat, green_turban, eyewear=bluesunglasses}
우선 장르별로 구별해준뒤에 values 를 사용하면 value들만 따로 Collection으로만들어줍니다.
values의 내부 모습 -> public val values: Collection<V>
잘라서 보기 (2)
clothes.groupBy { it[1] }.values결과: { [yellowhat, green_turban], [bluesunglasses]}
(실제 옷을 가지고 2차원 콜렉션으로 다시 바뀐다. 그리고 배열들이 같은 종류별로 묶여서 만들어진다.)
계산하기 쉽게 콜렉션으로 만들었으니 이제 계산만 해주면 됩니다.
그 다음 뒤에 콜렉션 함수 fold가 사용됩니다.
https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.collections/fold.html
fold - Kotlin Programming Language
kotlinlang.org
Accumulates value starting with initial value and applying operation from left to right to current accumulator value and each element.
초기값을 결정하고 왼쪽부터 시작해 오른쪽까지 계산을 합니다.
inline fun <T, R> Iterable<T>.fold(
initial: R,
operation: (acc: R, T) -> R
): R
groupBy와 마찬가지로 Iterable 인터페이스를 구현중인 클래스에서 사용 가능합니다.
clothes.groupBy { it[1] }.values.fold(1) { acc, v -> acc * (v.size + 1) } - 1v가 각 인덱스를 기준으로 잡힙니다.
{ [yellowhat, green_turban], [bluesunglasses]}
1번째 계산 [yellowhat, green_turban] -> size 2
2번째 계산 [bluesunglasses] ->size 1
1로 부터시작해서 값 * v.size+1 -> 결과 값 * v.size+1 ->..
이런식으로 진행이 되기 때문에 보기 쉽게 출력하자면 아래와 같이 됩니다.
fun solution(clothes: Array<Array<String>>)=
clothes.groupBy { it[1] }.values
.fold(1) { acc, v ->
println("acc:$acc , v:${v.size +1}")
acc * (v.size + 1) } - 1
결과:
acc:1 , v:3
acc:3 , v:2
5
참고로 -1 은 옷을 모두 입지 않는 경우를 생각해서 넣어주기 때문에 결과는 5가 나옵니다.
코틀린을 스트림 함수를 잘 사용하면 위와 같은 결과를 짧은 코드로 얻어낼 수도 있고,
java처럼 식으로 써내려가는것보단 사람이 실수할 확률이 적습니다
최종결과 : 5
알고리즘 2) 프로그래머스 베스트 앨범
https://programmers.co.kr/learn/courses/30/lessons/42579
코딩테스트 연습 - 베스트앨범
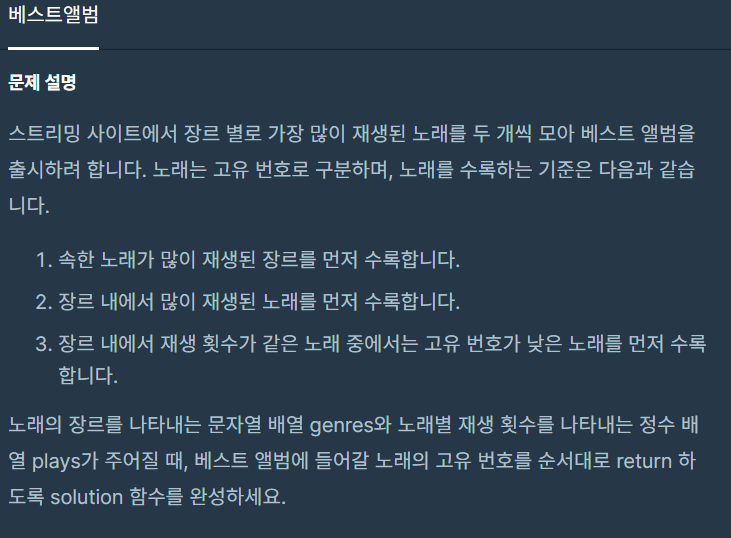
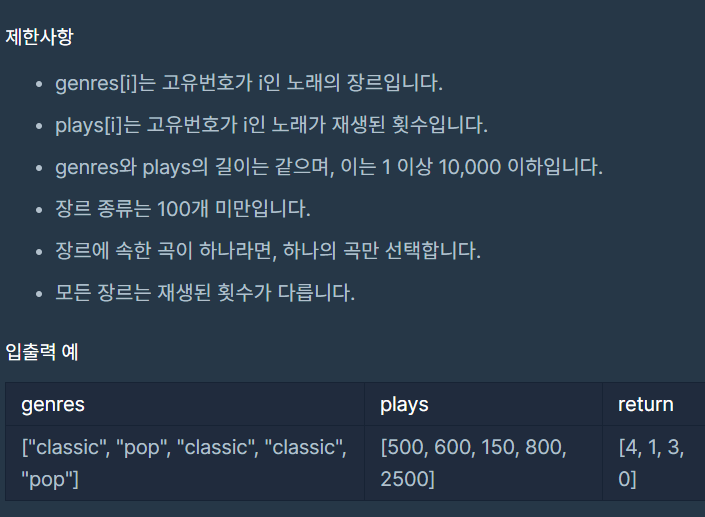
스트리밍 사이트에서 장르 별로 가장 많이 재생된 노래를 두 개씩 모아 베스트 앨범을 출시하려 합니다. 노래는 고유 번호로 구분하며, 노래를 수록하는 기준은 다음과 같습니다. 속한 노래가
programmers.co.kr
입출력 예
genresplaysreturn
| ["classic", "pop", "classic", "classic", "pop"] | [500, 600, 150, 800, 2500] | [4, 1, 3, 0] |
입출력 예 설명
classic 장르는 1,450회 재생되었으며, classic 노래는 다음과 같습니다.
- 고유 번호 3: 800회 재생
- 고유 번호 0: 500회 재생
- 고유 번호 2: 150회 재생
pop 장르는 3,100회 재생되었으며, pop 노래는 다음과 같습니다.
- 고유 번호 4: 2,500회 재생
- 고유 번호 1: 600회 재생
따라서 pop 장르의 [4, 1]번 노래를 먼저, classic 장르의 [3, 0]번 노래를 그다음에 수록합니다.
코틀린으로 풀이한건 다음과 같습니다.
fun solution(genres: Array<String>, plays: IntArray) =
genres.indices.groupBy { genres[it] }.toList().sortedByDescending { it.second.sumBy { plays[it] }}
.map {it.second.sortedByDescending { plays[it] }.take(2)}.flatten().toIntArray()
인자로 오는 값이 아래와 같다했을 때 계산해보겠습니다.
genres = ["classic", "pop", "classic", "classic", "pop"]
plays = [500, 600, 150, 800, 2500]
잘라서 보기 (1)
genres.indices.groubBy{genres[it]}
genres의 indices를 가져와서 genres[it]으로 맵으로 변환시켜줍니다.
indices의 설명은 아래에서 보실 수 있습니다.
https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.collections/indices.html
indices - Kotlin Programming Language
kotlinlang.org
indices의 모습은 이렇습니다.
public val <T> Array<out T>.indices: IntRange
get() = IntRange(0, lastIndex)
컬렉션의 범위 만큼 IntRange로 반환해줍니다.
size는 1부터 시작하는 갯수라서 인덱스 관련값을 구할때 -1하는 경우가 있지만
indices는 0..lastIndex 까지 반환해주기 때문에 위와 같은 경우가 줄어듭니다.
genres.indices.groupBy {
println("index:$it")
genres[it] }
결과:
index:0
index:1
index:2
index:3
index:4
{classic=[0, 2, 3], pop=[1, 4]}
index로 변환 후 맵으로 넣어주니
키 종류에 맞게 인덱스가 묶인것을 볼 수 있습니다.
잘라서 보기 (2)
List을 통해서 작업하기위해 Map변환 한것을 toList()로 List 바꿉니다.
그러면
{classic=[0, 2, 3], pop=[1, 4]} 이것이
[(classic, [0, 2, 3]), (pop, [1, 4])] 이렇게 바뀝니다.
Pair<out A, out B>
기존 key Value를 toList로 변환하니
List<Pair<K,V>>로 바뀝니다.
Pair의 설명은 아래와 같습니다.
public data class Pair<out A, out B>(
public val first: A,
public val second: B
) : Serializable
위와 같이 data class 로 정의가 되어있습니다.
인자로 first를 쓰면 A를 사용, second를 쓰면 B를 사용할 수 있게끔 됩니다.
다시 풀이 쪼개기로 돌아와서
genres.indices.groupBy { genres[it] }.toList().sortedByDescending { it.second.sumBy { plays[it] }}
sortedByDescending을 사용해줍니다.
https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.collections/sorted-by-descending.html
sortedByDescending - Kotlin Programming Language
kotlinlang.org
내림차순으로 정렬을 해주기 때문에 sort 가장 큰 값부터 내림차순이 됩니다.
람다안에 정렬할 기준으로
it.second.sumBy{plays[it]} 를 넣어줍니다. plays 안의 엘리먼트를 참조해서
정렬하기 때문에 아래와 같이 리스트가 변환됩니다.
[(classic, [0, 2, 3]), (pop, [1, 4])] 에서
[(pop, [1, 4]), (classic, [0, 2, 3])] 으로 변환 됩니다.
속한 노래가 가장 많이 실행되는 장르가 가장 앞으로 이동되었습니다.
잘라서 보기 (3)
genres.indices.groupBy {
println("indice:$it")
genres[it] }.toList(). sortedByDescending { it.second.sumBy { plays[it] }}
.map {
it.second.sortedByDescending { plays[it] }.take(2) }
이제 장르내에 노래중 가장 재생수가 많은 것을 내림차순 정리를 해주는 작업 입니다.
map은 Kotlin유저라면 많이 사용하니 별도의 설명은 제쳐두겠습니다.
여기서 take가 나오는데
Returns a sequence containing first n elements.
take는 파라미터의 n 값만큼 묶어서 반환을 해줍니다.
위 구문에서 map 안에서 사용했기 때문에 한 엘리먼트마다 배열로 받게 되어 아래와 같이 됩니다.
[(pop, [1, 4]), (classic, [0, 2, 3])]가
[[4, 1], [3, 0]] 으로 변환
이제 장르내에서 해당 장르 노래중에 가장 재생수가 많은 순으로 정렬이 되었습니다.
잘라서 보기(4)
genres.indices.groupBy { genres[it] }.toList().sortedByDescending { it.second.sumBy { plays[it] }}
.map {it.second.sortedByDescending { plays[it] }.take(2)}.flatten().toIntArray()
이미 나올 값은 다 나왔기 때문에 출력만 잘해주는 작업만 하면 됩니다.
방금 take 까지 [[4, 1], [3, 0]]라는 결과가 출력됩니다. 이제 2차원 배열을 1차열 배열로
만들어서 순위 리스트로 만드는 작업을 해주면 되는데
flatten() 이 1차열 배열로 쭉 나열해주는 작업을 해줍니다.
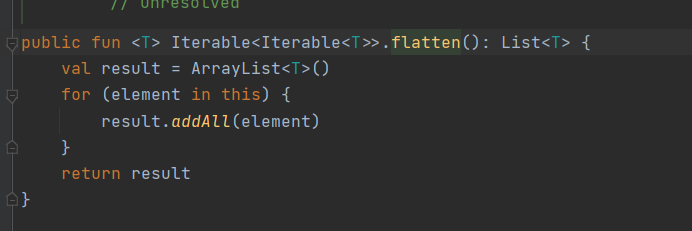
내부는 이렇습니다. val result 변수에 addAll을 해서 1차열 배열로 바꿔줍니다.
[[4, 1], [3, 0]] 이 2차원 배열이
[4, 1, 3, 0] 으로 바뀝니다.
toIntArray()는 사용하셔도 되고 생략하셔도 됩니다.
최종결과 :[4, 1, 3, 0]
블로그 포스팅을 하면서 다시 정리를 해봤습니다.
안드로이드 상위 1000개앱 80%가 Kotlin으로 이루어져 있다고 합니다.
그만큼 많이 사용하는 이유가 있겠지요?
Kotlin을 공략하는 자가 안드로이드 개발에서 더 좋은 효율을 낼거라 생각합니다.
'코틀린 Kotlin' 카테고리의 다른 글
| kotlin (6) - lateinit 과 by lazy 용도 간단 정리 (0) | 2021.06.05 |
|---|---|
| kotlin (5) Object 와 Companion Object (0) | 2021.06.04 |
| Kotlin (4) - 안드로이드의 코틀린 (Google IO) (0) | 2021.05.29 |
| Kotlin (3) - 코틀린의 repeat와 Pair를 알아보자 (백준 1003) (0) | 2021.05.23 |
| Kotilin (2) - 코틀린 피보나치 수열 및 1..10 정리 (백준 11727) (1) | 2021.05.21 |